"오늘은 케글을 사용한 크롤링을 통해 네이버 시리즈에 있는 작품명과 이미지를 가져와 보자
각 코드의 해설은 주석에 있다"
사용할 크롤링 방식: BeautifulSoup
첫번째로 install을 한다
!pip install newspaper3k
임포트를 한다
import requests
import pandas as pd
from newspaper import Article
from bs4 import BeautifulSoup
크롤링할 url을 넣는다
url = 'https://series.naver.com/novel/categoryProductList.series?categoryTypeCode=genre&genreCode=208'
우리가 크롤링할 페이지 url로 들어가 우리가 가져올 이미지와 제목 부분으로 들어오면
<ul> 태그 class="lst_list" 안에 <li> 태그 안에
<img> 태그 안에 사진(src), 제목(art)가 있는걸 확인할 수 있다.
이걸 잘 기억하자!!!
다음으로 헤더를 붙이고 리퀘스트 요청을 보낸 다음
데이터가 잘 들어오는지 확인하기 위해 print를 해본다
# 헤더를 붙여서
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
# 리퀘스트 요청을 보냄
WebToon = requests.get(url, headers=headers)
# 데이터 잘 들어왔는지 확인 위해 print
print(WebToon.text)
print를 해보면 우리가 원하는 데이터가 잘 print 되는걸 볼 수 있다
그러면 이제 src, alt 부분만 가져와보자

객체를 생성하고
# html 파싱을 위한 객체 생성
soup = BeautifulSoup(WebToon.content, 'html.parser')아까 우리가 크롤링할 페이지 url로 들어가 우리가 가져올 이미지와 제목 부분으로 들가서 확인했던
class인 lst_list의 <li> 태그까지 선택 해준 다음
# ()안에는 .클래스 이름, 태그 이름
WebToon_list = soup.select('.lst_list li ')
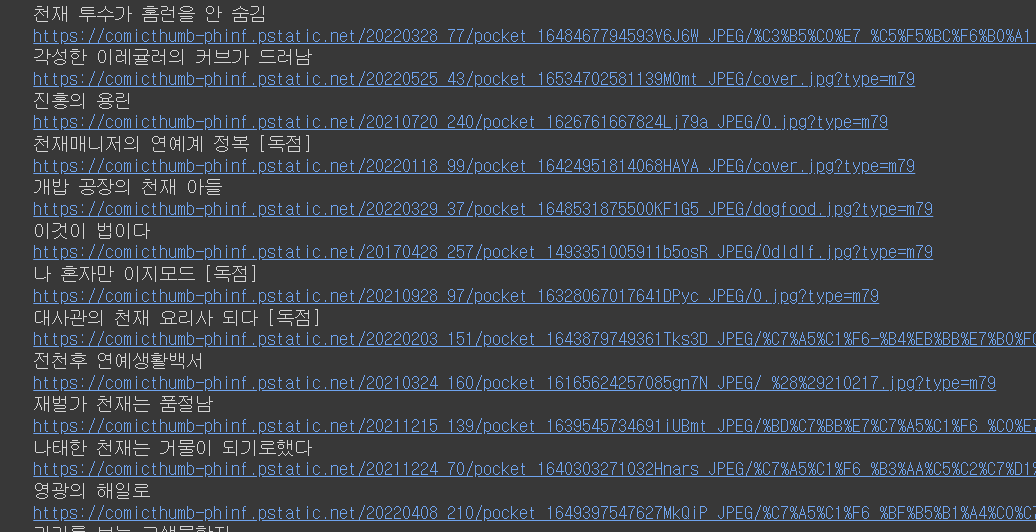
# print(WebToon_list)for 문으로 우리가 가져올 부분인 alt와 src를 print 해주면 끝난다
# for문으로 태그들을 돌리고 그중 a태그를 선택하고 그 중에 title를 가져온다
for toon_tag in WebToon_list:
print(toon_tag.img.get('alt'))
print(toon_tag.img.get('src'))
결과
댓글